Проблема клієнта
Клієнт із США потребував можливості перевіряти коректність своїх бізнес-операцій та вхідних платежів, а також проводити аналіз цін конкурентів на товари роздрібної компанії. Подібні виклики ми вже вирішували в інших проєктах — наприклад, під час створення системи обробки ACH-платежів для фінансової платформи, де критичною була точність транзакцій від початку до кінця, або при розробці автоматизованого аудиторського рішення для сімейного інвестиційного фонду, де основним пріоритетом були відповідність регуляторним вимогам та прозорість фінансової звітності.
Якщо клієнт працював у сфері e-commerce через Amazon, Shopify, eBay, Etsy та відстежував усі транзакції в Quiltt.io, він міг надати нам права доступу для перегляду доступних даних. Щоб згенерувати статистику, потрібно було завантажити дані клієнта — значні обсяги та різні типи даних із кількох систем, які надають фінансову інформацію у форматі read-only (замовлення, деталі замовлень — тобто які саме товари були продані, платежі, виплати, повернення тощо). Основні проблеми клієнта полягали в наступному:
-
Складність у подоланні обмежень API при отриманні великих обсягів даних, що спричиняло затримки та неповні набори даних.
-
Потреба в автоматичних оновленнях та синхронізації історичних і щоденних даних.
-
Відсутність ефективної архітектури для роботи з різними обмеженнями API та масштабування під зростаючі обсяги даних.
-
Вимоги до стійкості системи: повторні спроби, відновлення після помилок та мінімальний простій під час синхронізації даних.
Коротко кажучи, клієнту була потрібна гнучка мікросервісна архітектура для оптимізації швидкості отримання даних із кількох API та забезпечення стабільності в умовах API-обмежень і навантажень великими даними на інфраструктурі Azure Cloud.
Виклики
Оскільки наш клієнт активно використовував кілька API-сервісів (eBay, Etsy, Amazon, Shopify, Quiltt.io) для бізнес-операцій та аналітики, перед нами постали такі технічні виклики:
1. Обмеження API та неповні дані
-
Кожна інтегрована система мала суворі обмеження на кількість запитів (наприклад, Amazon встановлював фіксовану кількість запитів на хвилину для кожної кінцевої точки, Shopify — обмеження для кожного клієнта тощо).
-
Деякі інтеграції час від часу повертали неповні дані з eBay, Etsy або Amazon.
-
У випадку з eBay доводилося надсилати повторні запити для обробки кодів помилок, таких як 400 Bad Request, 404 Not Found чи 500 Internal Server Error.
-
Виникла потреба у застосуванні архітектурних патернів для управління обмеженнями API при багатоканальних інтеграціях.
2. Складність підключень та інтеграції
-
Потрібен був уніфікований набір функцій підключення клієнтів для підтримки кількох мов програмування та фреймворків.
-
Питання наскрізної підключуваності слід було делегувати інженерам інфраструктури або спеціалізованим командам.
-
Система мала підтримувати підключення до хмари та кластерів у рамках застарілого застосунку, який було складно модифікувати.
3. Надійність та відмовостійкість
-
Висока надійність вимагала автоматизованих перевірок цілісності та механізмів повторних спроб у разі збоїв.
-
Потрібно було створити кілька пулів споживачів, щоб відповідати суворим вимогам до продуктивності та ізолювати проблеми, забезпечивши, щоб збої в одній черзі не впливали на інші.
4. Вимоги до компонента Sidecar
-
Деякі компоненти мали використовуватися спільно в застосунках, розроблених різними мовами чи фреймворками, тому підхід sidecar був оптимальним.
-
Компонент, яким керувала віддалена команда чи зовнішня організація, потрібно було інтегрувати так, щоб він міг оновлюватися незалежно, не порушуючи роботу основного застосунку.
-
Деякі функції мали розміщуватися поруч з основним застосунком, розділяючи його життєвий цикл, але залишаючись незалежно розгортаними.
-
Була потрібна тонка настройка керування ресурсами (наприклад, управління пам’яттю для кожного компонента), чого вдалося досягти завдяки розгортанню компонента як sidecar.
У результаті, через різні обмеження систем, проєкт отримував дані повільніше, ніж міг би, а повнота даних не була гарантованою, що впливало на релевантність статистики.
Подібна складність виникала і в інших наших проєктах, наприклад, під час розробки IoT-конвеєра даних для енергетичної компанії на базі Azure Cloud, де потрібно було обробляти різноманітні потоки сенсорних даних за жорстких вимог до продуктивності та надійності.
Початкова інфраструктура та архітектура
Спочатку існувала мережа воркерів, кожен із яких обробляв свій тип даних та конкретну інтеграцію. Усі обмеження швидкості оброблялися однаково, виходячи з найгіршого сценарію (1 запит на хвилину для всіх), що гарантувало надійність, але призводило до дуже повільної роботи.
Наш підхід до проєкту
Наша спеціалізована команда розробників чітко усвідомлювала завдання — забезпечити швидше отримання даних з API Amazon, eBay, Etsy, Shopify та Quiltt.io.
Amazon, Shopify, eBay, Etsy та Quiltt.io були інтегровані в цей проєкт зі збирання даних. У середньому оброблялося близько 100 000 записів на одного підключеного клієнта, і ця кількість зростала з кожним новим клієнтом. Під час підключення завантажувалися всі історичні дані, а надалі щоденні оновлення фіксували всі зміни.
На етапі проєктування ми розробили комплексний план реалізації, щоб гарантувати ефективність, масштабованість і бізнес-цінність. Основними напрямами роботи були:
-
Аналіз системи та проєктування архітектури: проведено глибокий аналіз існуючих систем і спроєктовано оптимальну інтеграційну архітектуру відповідно до бізнесових і технічних вимог.
-
Розробка індивідуальних сервісів: створені спеціалізовані сервіси для обробки фінансових даних, формування звітів та забезпечення відповідності галузевим стандартам.
-
Експертна команда доставки: зібрана міжфункціональна команда, здатна швидко впроваджувати рішення, адаптуватися до нових вимог і забезпечувати постійну підтримку.
-
Інтеграція з корпоративними системами: нові цифрові компоненти безшовно інтегровані з існуючими системами клієнта — on-premise, CRM, ERP та іншими корпоративними платформами для оптимізації обміну даними й підвищення ефективності внутрішніх процесів.
-
Галузева та технологічна експертиза: використано специфічні знання для створення MVP, перевірки припущень зі стейкхолдерами та регулярних презентацій дорожньої карти для прозорості й узгодженості.
-
Повний цикл розробки програмного забезпечення: спроєктовано та розгорнуто спеціалізовані програмні компоненти, включаючи вебпортали, мобільні застосунки, API та системи аналітики даних, відповідно до потреб клієнта.
-
Висока надійність та стійкість: реалізовано автоматизовані перевірки цілісності даних, механізми повторних спроб і відновлення після помилок для мінімізації простоїв та забезпечення стабільності системи.
-
Розширена аналітика та звітність: забезпечено швидкий і точний доступ до аналітики та статистики для своєчасного прийняття рішень на основі даних.
-
Точність і повнота даних: підвищено якість і надійність бізнес-статистики завдяки надійним механізмам валідації.
-
Масштабованість і готовність до зростання: архітектура розроблена з урахуванням можливості масштабування відповідно до збільшення обсягів транзакцій та розширення клієнтської бази.
-
Ефективність витрат: знижено витрати на підтримку й інтеграцію завдяки повторному використанню кодової бази та стандартизованим патернам проєктування.
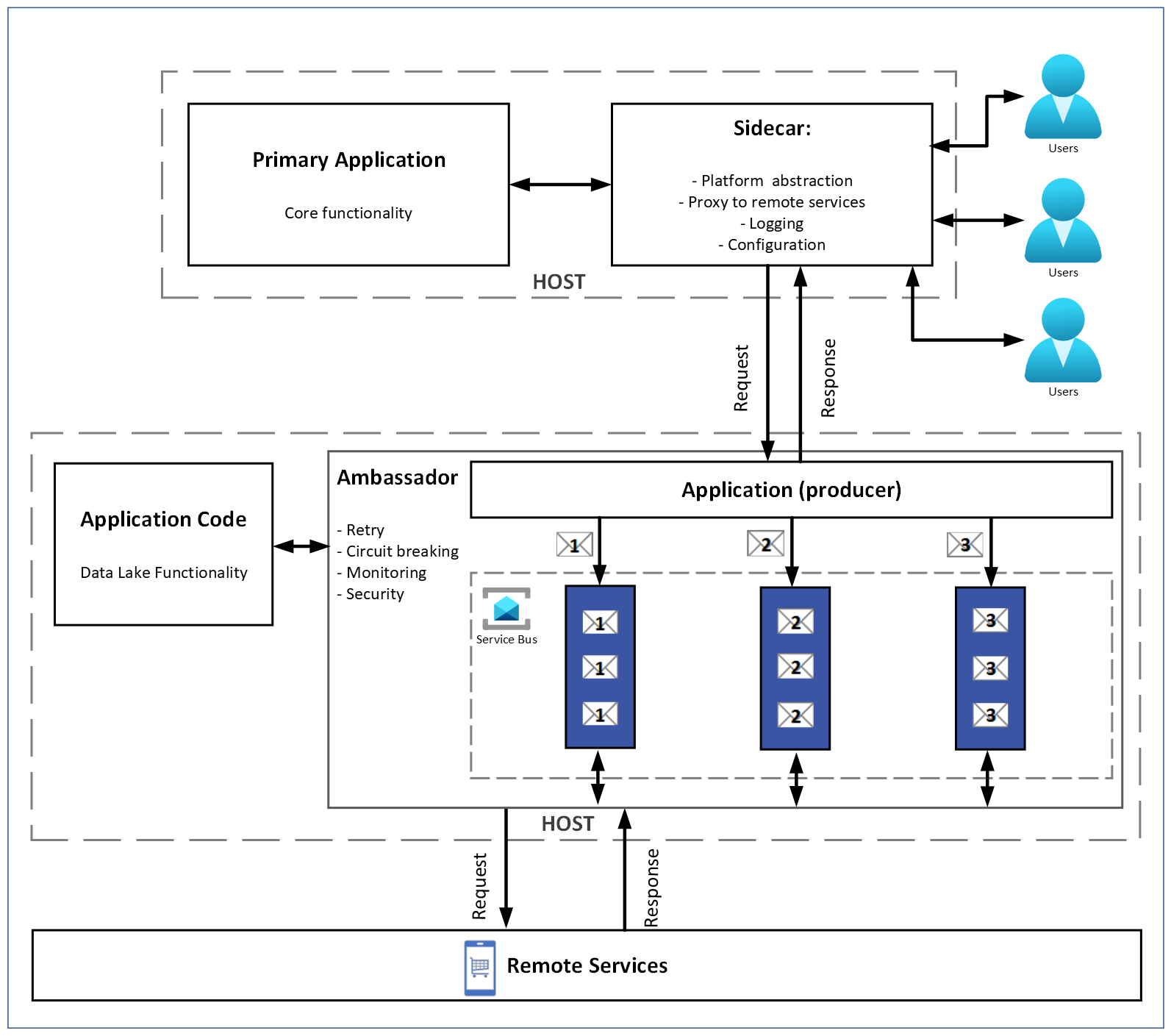
Архітектура рішення
Мікросервісна архітектура для інтеграції e-commerce даних:
-
Окремі мікросервіси для обробки статистики та моніторингу.
-
Сервіс Ambassador для кожної інтеграції, що забезпечує масштабованість залежно від навантаження.
-
Один мікросервіс відповідає за обробку одного типу завдань, пов’язаного з інтеграцією. Тип завдання жорстко прив’язаний до мікросервісу. Це означає, що кожен мікросервіс є спеціалізованим і виконує лише один тип завдань. У разі високого навантаження чи зростання потреб мікросервіс можна масштабувати (горизонтально або вертикально), щоб підтримати продуктивність.
Три оркестратори:
-
При підключенні клієнта — команда для отримання всіх даних.
-
Щоденний тригер — команда для оновлення даних.
-
Режим парсингу презентацій для потенційних клієнтів.
Мікросервіси комунікували за потреби через черги повідомлень.
Було три рівні. Priority queue використовувалась для визначення порядку вилучення та обробки даних. Це виконувалося майстер-мікросервісом у патерні master-worker. Обробка починалася з періодів: день, місяць, півріччя, рік тощо. Додатково пріоритезація також виконувалася на стороні Ambassador, який керував розподілом швидкості. Логіка черги була наступною:
- Orders
- Transactions
- Remains
- Returns
- Payouts
Order Items — після того, як замовлення були оброблені, мали найвищий пріоритет щодо фінтех-даних. Demo messages виконували роль третьої черги обробки з найвищим пріоритетом у демо-режимі. Для демо-цілей система обмежувала кожного клієнта 100 запитами на маркетплейс.
Використання Azure Service Bus було наступним. Було застосовано дві черги. Перша черга використовувалась для завдань (майстер-додаток, де consumer залучався рідко — лише тоді, коли було необхідно запустити наступний мікросервіс у ланцюгу обробки, наприклад orders). Друга черга використовувалась для повідомлень про завершення завдання.
Ми застосували патерн Competing Consumer у поєднанні з мікросервісами для отримання даних і Ambassador. Усі робочі процеси надсилали свої запити до Ambassador, і він визначав, у якому порядку та в якій пропорції вони будуть оброблені.
Патерн Sidecar застосовувався для того, щоб одночасно розгорталися обидва залежні застосунки (мікросервіси), Ambassador і робочі для обробки даних.
Додаткові правила, розроблені під час реалізації:
- Amazon — обмеження швидкості застосовувалися для кожного ресурсу (типу даних). Основне завдання Ambassador у цьому випадку — сповільнювати робітника до темпу, прийнятного для інтеграції.
- Shopify — діяв єдиний глобальний ліміт для всіх запитів. У цьому випадку Ambassador керував розподілом пріоритетів.
Загалом, розробка MVP цього компонента зайняла 3 місяці.
Використані технології
У рамках наших послуг з технологічного консалтингу ми обрали кілька ключових технологій для цього проєкту. Патерн Ambassador вирішив проблему різних обмежень у різних системах, мінімізуючи кількість та складність коду.
Завдяки Ambassador один модуль коду обробляв замовлення (зі своїми обмеженнями), інший — Shopify (зі своїми обмеженнями) тощо, уникаючи множинних та заплутаних кодових баз. Для Shopify запити могли розподілятися між серверами, і була потрібна синхронізація між ними. Ambassador виступав основним шлюзовим сервером для кожної інтеграції (точкою проходження даних, що ставилися у чергу до моменту обробки).
Priority Queue дозволила розподіляти обмеження на запити логічно та динамічно відповідно до бізнесових потреб, на основі заздалегідь визначених правил.
Приклад: перевірка актуальності цін для груп товарів власника магазину порівняно з аналогічними товарами конкурентів на перелічених e-commerce платформах, з урахуванням наявності товарів на складі. Власник магазину визначає пріоритетність груп товарів для перевірки.
Запити на замовлення та деталі замовлень могли оброблятися у співвідношенні 1:3. Після повного завантаження замовлень залишкова квота перерозподілялася на деталі, прискорюючи загальний процес отримання даних.
Інші патерни та технології:
Відмовостійкість та аварійне відновлення:
-
Логіка керування оркестратором повідомлень.
-
Завантаження даних поділялося на блоки (батчі, на які ділили процес отримання даних).
-
Розмір блоків визначався середнім обсягом даних.
-
Кожен блок завантажувався як єдине ціле; у разі неповного завантаження він повторювався.
-
Після завантаження виконувалася перевірка цілісності даних; у разі збою спрацьовувала логіка очікування та повтору.
-
Якщо повідомлення не вдавалося обробити тричі, надсилався email-алерт у службу підтримки клієнта; інші блоки продовжувалися в роботі.
-
Усі процеси були розгорнуті на інфраструктурі Microsoft Cloud. Azure Blob Storage зберігав кілька копій даних, щоб забезпечити довговічність і доступність навіть під час збоїв. Різні варіанти реплікації надавали можливість обрати оптимальний рівень стійкості.
Процес впровадження
-
Етап discovery та проєктування архітектури: клієнт описав проблему, ми проаналізували наявну інфраструктуру, провели кілька днів брейнштормів, запропонували рішення та реалізували його.
-
Тестування інтеграцій та стабільності потоків даних: запускалося на існуючих акаунтах клієнта з подальшою перевіркою отриманих даних.
-
Міграція із застарілих систем або попередніх інтеграцій: процес був спрощений — для інших мікросервісів потрібно було лише замінити цільовий URL.
-
Реалізація та тестування proof of concept у партнерських магазинах.
Ми застосували патерн Competing Consumer у поєднанні з мікросервісами для отримання даних та Ambassador.
Цей патерн особливо ефективний, коли:
-
робоче навантаження застосунку можна розділити на асинхронні завдання,
-
завдання є незалежними та можуть виконуватися паралельно,
-
обсяг навантаження є дуже змінним і потребує масштабованості,
-
рішення має гарантувати високу доступність і стійкість навіть у випадку збоїв при виконанні окремих завдань.
Ambassador виступав координатором, який застосовував специфічні правила для інтеграцій і контролював темп виконання завдань воркерами.
Результати та бізнес-ефект
-
Середній час початкового отримання даних і формування статистики скоротився з 24 годин до 12.
-
Клієнт отримав можливість завантажувати та агрегувати великі обсяги різноманітних даних із кількох систем.
-
Вони здобули стійку систему з автоматизованими повторними спробами, відновленням після помилок та мінімальними простоями.
-
Реалізовано масштабовану, гнучку мікросервісну архітектуру для оптимізації багатоканального збору даних.
-
Забезпечено швидше отримання даних з API Amazon, eBay, Etsy, Shopify та Quiltt.io.
-
Бізнес отримував дані раніше, що дало змогу ухвалювати рішення швидше.
-
Покращено точність і повноту статистичних даних.
-
Час збору повного набору даних і формування звітів скоротився удвічі.
-
Прискорено ухвалення бізнес-рішень завдяки ранньому доступу до аналітики.
-
Реалізована цифрова трансформація шляхом впровадження нових технологій та інноваційних рішень для покращення бізнес-процесів і стратегії клієнта.
-
Зросла продуктивність завдяки впровадженню рішень для оптимізації внутрішніх процесів та автоматизації завдань.
-
Знижено витрати шляхом оптимізації інфраструктури та впровадження ефективних рішень.
-
Покращено взаємодію з клієнтами завдяки якіснішому сервісу та новим каналам комунікації.
-
Досягнута цифрова трансформація, що забезпечила конкурентну перевагу завдяки сучасним технологіям та цифровим рішенням.
У рамках фінтех-розробки замість негайного переходу до реалізації наша команда провела ретельне дослідження open-banking сервісів і запропонувала Quiltt.io як оптимальне рішення. Це забезпечило надійну та масштабовану основу для фінансового продукту клієнта.
Досліджуйте наші подібні проєкти, щоб побачити, як інші бізнеси вже виграли від наших послуг у сфері розробки програмного забезпечення. Якщо ви зацікавлені у тому, як наша експертиза може прискорити вашу цифрову трансформацію, відвідайте сторінку Наші Ціни, щоб обговорити свій проєкт із нашою командою!
Yuliia Suprunenko