Наш клієнт (NDA), компанія з телекомунікаційної галузі, прагнула вирішити важливу проблему, з якою стикаються багато компаній у цьому секторі — прогнозування та управління тарифними планами, а також створення нових тарифних планів, придатних як для споживача, так і для компанії. У цьому кейсі розглядається інноваційне рішення, розроблене для розширення можливостей нашого клієнта у сфері прогнозування та управління тарифними планами, і пропонується комплексний погляд на досягнуту трансформацію.
ОСНОВНІ ЗАВДАННЯ, ЩО СТОЯЛИ ПЕРЕД КОМАНДОЮ
- Імплементація методу в модель, який може прогнозувати задані події щодо тарифних планів за атрибутами та іншими заданими критеріями.
- Розбиття даних на найменші складові — атрибути, для ефективної інтерпретації результатів штучним інтелектом.
- Інтегрування в модель можливість відстежувати сезонність в оброблюваних даних.
ЩО БУЛО ЗРОБЛЕНО
Наша команда розробників розпочала шлях реалізації чотирьох окремих алгоритмічних кроків.
Для розробки моделі були реалізовані основні сімейства алгоритмів:
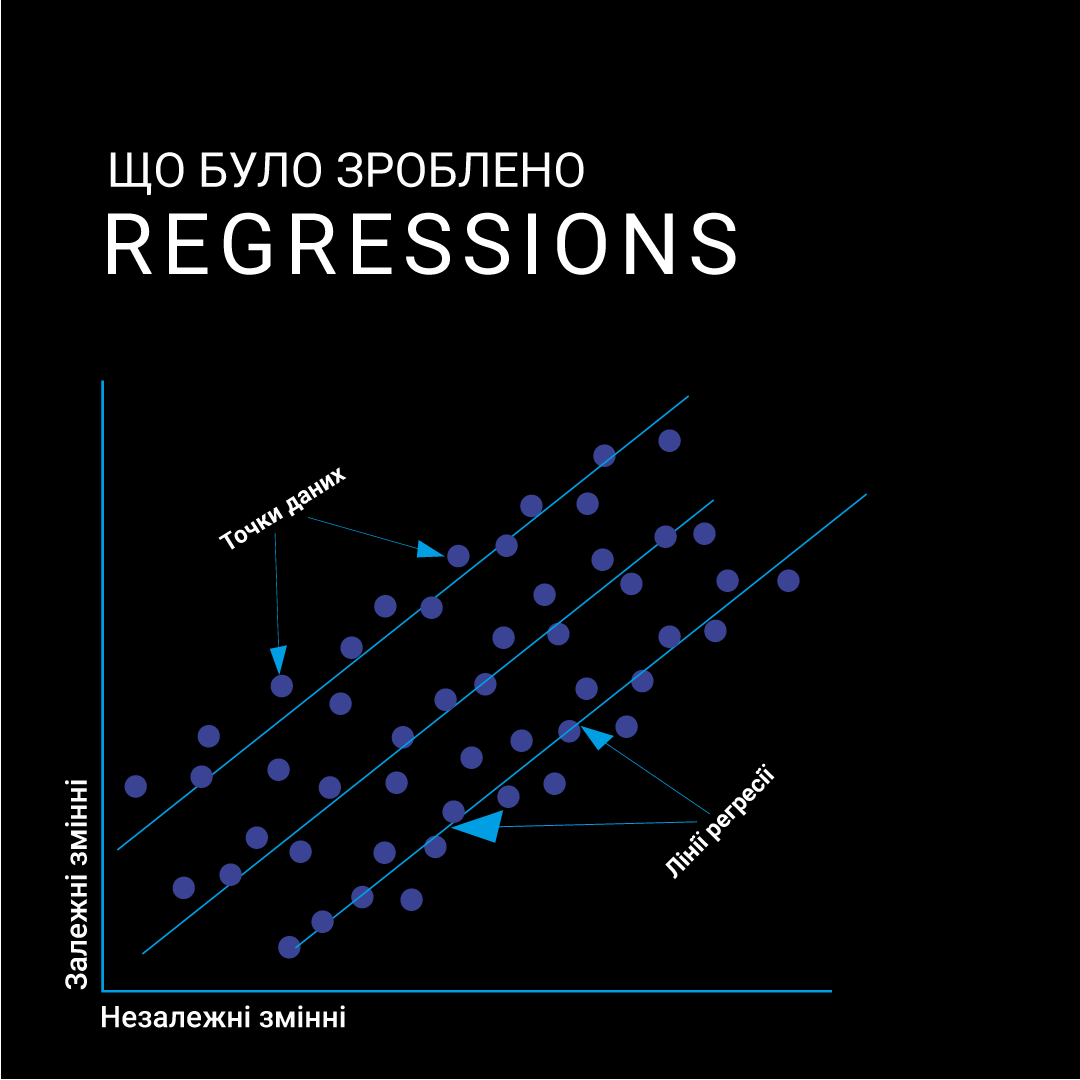
Регресії
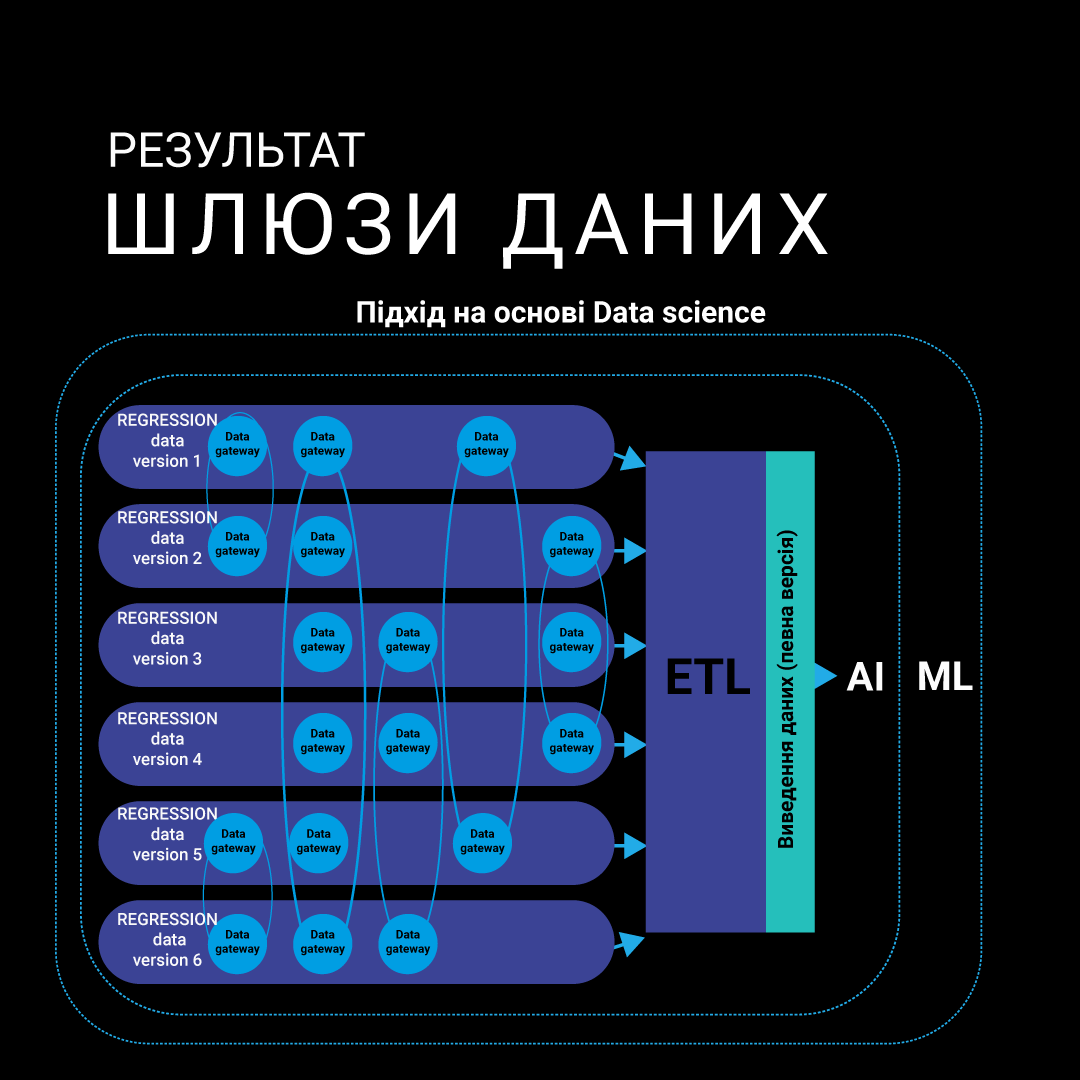
В основі нашого процесу побудови моделі лежить регресія - метод, який ми будемо використовувати для прогнозування різних значень та атрибутів, пов'язаних з тарифами. Для вилучення, обробки та агрегування необхідних даних ми використали інструмент Extract, Transform, Load — (ETL). Команда реалізувала пошук даних з різних типів джерел та надала їх у прогностичній структурі для заповнення версії Data Science Model за допомогою розроблених стабільних версій ETL-шлюзів обробки даних для циклу регресійних даних. Наприклад, ми взяли 1 терабайт даних для кожного циклу регресії.
Ці агреговані дані, представлені в простих типах даних, є основою для побудови прогнозів. За допомогою регресійних моделей ми можемо спрогнозувати витрати на обладнання, спрогнозувати потенційний дохід від тарифних планів або планів, які не користуються попитом і не є доцільними для використання тощо. Така модель гарантуватиме прийняття обґрунтованих рішень на основі оброблених даних.
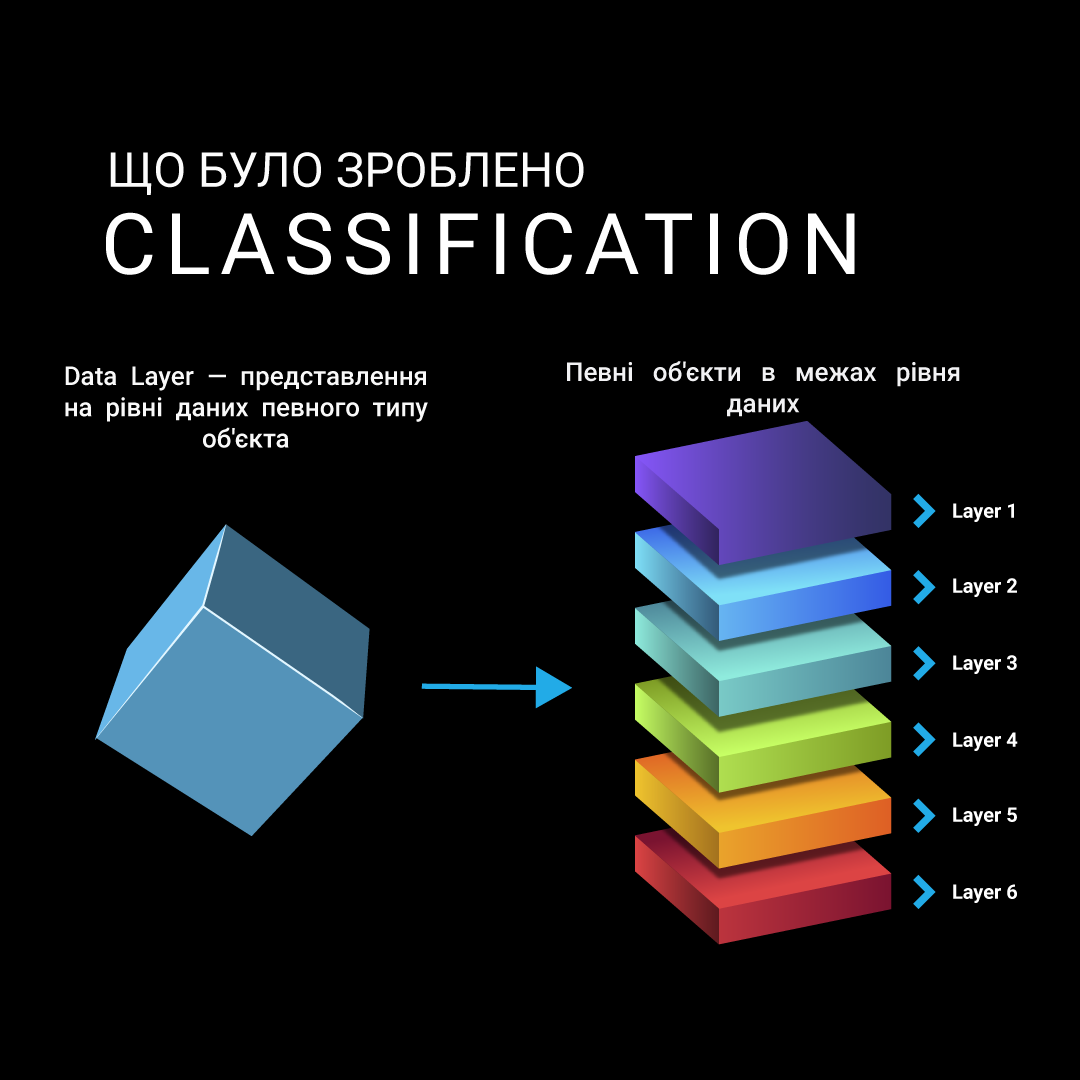
Класифікація
У телекомунікаційному секторі надзвичайно важливо правильно реалізувати складний взаємозв'язок атрибутів, які безпосередньо впливатимуть на формування тарифів. Ці атрибути були згруповані в шари сутностей, які були організовані в ієрархію даних. Для забезпечення точної версії результатів регресії на рівнях сутностей було впроваджено контроль версій для CRUD-операцій. Цей процес класифікації дозволяє клієнту будувати прогнози на основі різноманітних примітивних значень і атрибутів, що сприяє комплексному підходу до управління тарифами, оскільки розділення і запис примітивних типів даних покращило якість машинного навчання. У телекомунікаційній галузі його можна використовувати для класифікації поведінки клієнтів, допомагаючи передбачити бажані пакети даних або тарифи для міжнародних дзвінків та інших класів.
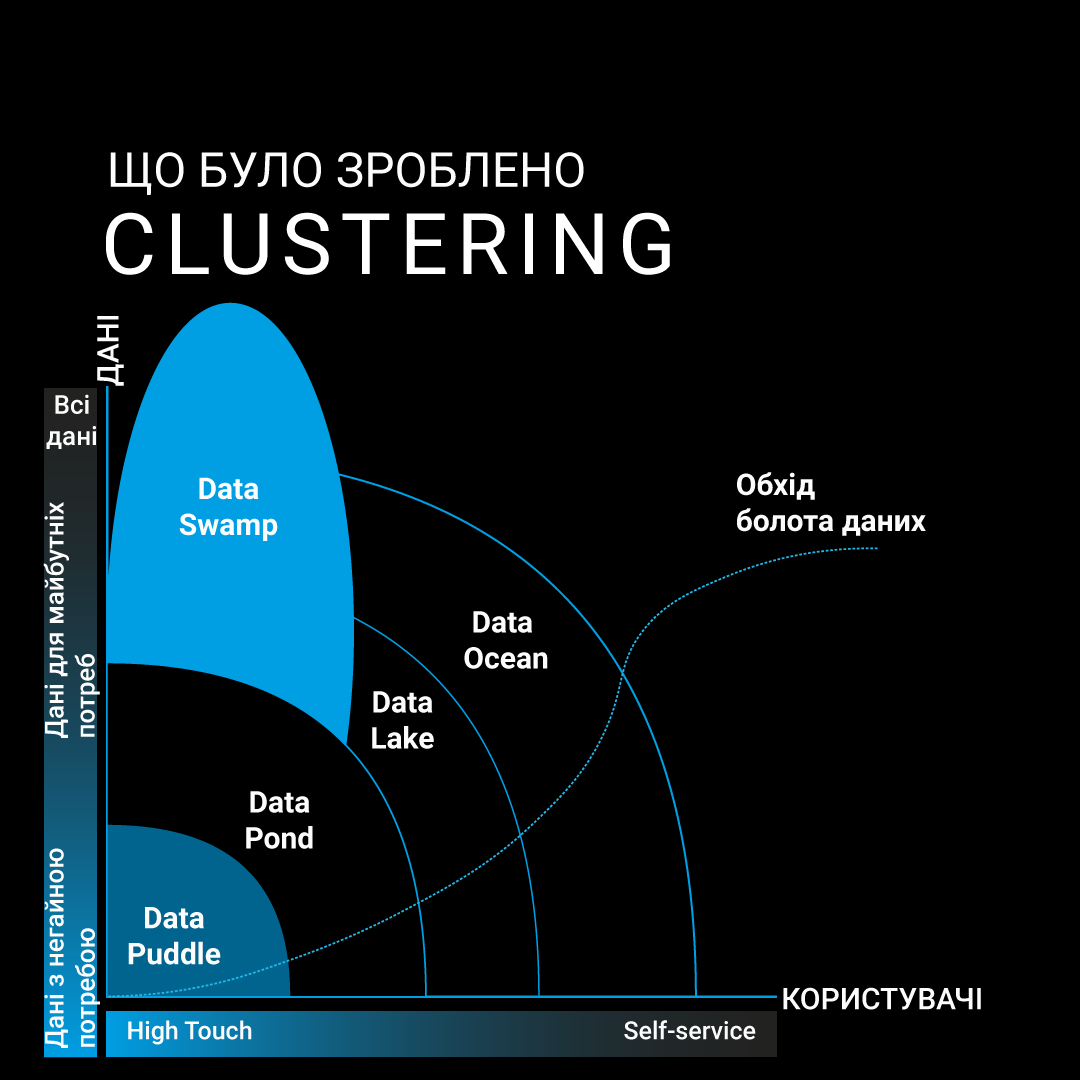
Кластеризація
Після успішної класифікації даних їх можна використовувати для побудови надійних моделей прогнозування. Хорошим прикладом є те, як ми кластеризували тарифні плани для трьох різних категорій клієнтів.
- Для бізнесу. Щоб уникнути "болота даних" та забезпечити оптимально контрольоване використання хмарних сервісів, ми розділили та кластеризували дані в "Океані даних".
- Для користувачів. Для швидкого доступу до даних Data Puddle ми класифікували дані в рівнях сутностей, щоб при виконанні операцій INSERT INTO на рівні сервера час відгуку становив до 280 мс.
Іншими словами, ці кластери — це озера даних, які зберігалися в окремих базах даних, що працювали синхронно через Kerberos (протокол, який також використовувався на етапі регресії) для безперебійного управління даними. Шлюзи даних з обмеженими визначеними можливостями були розроблені на стороні замовника за допомогою шлюзів з рішення ETL. Бази даних повертають результати асинхронно, забезпечуючи оптимальну швидкість доставки результатів.
Такий кластерний підхід дозволяє індивідуалізувати управління тарифами, обслуговуючи різні сегменти клієнтів, а для забезпечення якісного процесу кластеризації та надійної роботи програмного забезпечення ми використали технології Kubernetes та Azure Active Directory.
Наша інфографіка показує, як в кінцевому підсумку можна обійти “болото даних”. Якщо цей обхідний шлях не спрацьовує, тоді необхідна повторна кластеризація, класифікація та регресія.
Часові послідовності
Розроблена модель дозволяє аналізувати часові послідовності з урахуванням сезонних залежностей, які впливають на кластери даних. Це особливо важливо при врахуванні державних свят та вихідних, які можуть суттєво впливати на вартість дзвінків та структуру використання. Додавши святкові та вихідні дні з певними атрибутами, такими як назва та дата, ми отримали точну картину того, як ці події впливають на використання тарифів.
Крім того, ми побачили передбачувані залежності майбутніх подій з певним відсотком настання, оскільки ми фіксуємо повторення в класифікованих даних для заданих історичних подій в порядку настання змін в часовому ряді для певного діапазону простих даних і в певному порядку зміни станів в шарах відносно суб'єкта.
Зокрема, розроблена модель аналізувала дані з прив'язкою до заданої геолокації та робила прогнози на основі фінансового стану клієнтів клієнта в різні періоди часу. Такий підхід дозволив клієнту оптимізувати ціноутворення в залежності від періоду часу та економічної ситуації.
Наприклад, з цих даних ми можемо побачити, як розвивається бізнес або особа, що належить до певної галузі в якійсь країні, або що в певних галузях є сезонний попит на пропозицію нашого клієнта, від підприємств та працівників, що працюють в цій галузі. Коли попит на послуги чи товари зростає або навпаки, клієнт має можливість надавати більш якісні та актуальні послуги для кожного користувача.
Розробка моделі на основі даних
Розробка цієї моделі значною мірою спиралася на дані та їхні залежності. Забезпечення унікальності даних без дублювання було надзвичайно важливим, оскільки від цього залежала релевантність результатів. Використання простих типів даних та оцифрування всіх даних підвищило ефективність моделі.
Машинне навчання та тренування
Модель була ретельно навчена за допомогою методів машинного навчання, що дозволило їй виявляти нові закономірності в даних. У процесі навчання проводились постійні експерименти та вдосконалення, що робило модель все більш точною. Хоча потенціал моделі безмежний, він залишається обмеженим наявними навчальними даними. У прагненні до досконалості необхідна людська перевірка, поки точність моделі не перевищить 99%. Обмежений обсяг даних для аналізу моделлю становив 10 ТБ.
Оптимізація часу повернення даних
Команда NetLS розробила та запустила паралельні процеси повернення даних з оперативної пам'яті та бази даних.
Дані, які запитувалися найчастіше, зберігалися в оперативній пам'яті для забезпечення швидкого повернення.
Швидка обробка інформації відображається на швидкості повернення даних:
- Менше 160 мс з оперативної пам'яті
- Менше 280 мс з бази даних
- Менше 380 мс з бази даних
Всі дані мають позначку часу і видаляються з оперативної пам'яті протягом 10 секунд, якщо їх не запитують, з подальшим кешуванням до 12 годин згідно з Data Puddle. Це рішення гарантує, що наш клієнт може швидко отримати доступ до необхідних даних і використати їх у потрібний момент.
Звітність
Крім того, фахівці NetLS реалізували інтеграцію з MS Power BI. Це рішення підвищило зручність візуалізації попередніх даних. MS Power BI дозволила нам додати додаткові подальші фільтри до існуючих даних: Часові ряди -> Кластеризація -> Класифікація.
РЕЗУЛЬТАТ
Чотириступеневий алгоритмічний підхід дозволяє нашому клієнту не тільки прогнозувати та управляти тарифами, але й надавати клієнтам рішення, які максимально задовольнять їх і не дадуть їм переключитися на конкурентів.
Інтеграція моделі на основі ML поглибила розуміння клієнтом сезонних залежностей, що впливають на розрахунки тарифів, і, таким чином, підвищила актуальність та ефективність існуючих тарифів, одночасно полегшивши створення індивідуальних альтернатив.
Крім того, ця модель пропонує клієнту гнучкість у включенні користувацьких атрибутів на основі спеціального шаблону в кластерну структуру. Така адаптивність розширює спектр можливостей, дозволяючи клієнту вдосконалювати свої пропозиції та залишатися гнучким в умовах волатильності ринку.
Зрештою, це унікальне рішення є значним кроком вперед у прийнятті рішень на основі даних та вдосконаленні білінгових процесів мобільних операторів, дозволяючи клієнту підвищити ефективність та конкурентоспроможність у своїй галузі, а не лише звертатися до традиційної бізнес-аналітики, яка займає багато часу для аналізу.