The client’s problem
The USA client required the ability to verify that their business operations and incoming payments were in order, as well as to conduct an analysis of competitor prices for goods of a retail company. Similar challenges have arisen in our other projects — for example, in building an ACH payment processing system for a financial platform, where end-to-end transaction accuracy was critical, or in developing an Automated auditing solution for a family investment fund, where compliance and transparency of financial records were the main priorities.
If a customer operated in e-commerce via Amazon, Shopify, eBay, Etsy, and watch all transactions across Quiltt.io, they could grant us access rights to view their available data. To generate statistics, it was necessary to download the customer’s data — a large amount and a variety of data types from multiple systems that provide read-only financial data securely (orders, order details — i.e., which specific items were sold — payments, payouts, refunds, etc.). Main problems for our client were:
- Struggles with overcoming API rate limits when retrieving large volumes of data, causing delays and resulting in incomplete datasets.
- The need for automatic updates and synchronization of historical and daily data.
- Lacks an effective architecture for handling various API constraints and scaling to accommodate growing data volumes.
- System resilience requirements ensure retries, error recovery, and minimal downtime during data synchronization.
In short, the client required a flexible microservices-based architecture for optimization of data retrieval speed from multiple APIs and ensuring stability in the face of API constraints and big data workloads for the Cloud Azure infrastructure.
The challenges
As our client actively uses multiple API services (eBay, Etsy, Amazon, Shopify, Quiltt.io) for business operations and analytics, this presented several technical challenges for us:
1. API limitations and incomplete data
- Each integrated system had strict request limits (e.g., Amazon sets a fixed number of requests per minute per endpoint, Shopify sets a limit per client, etc.).
- Some integrations occasionally returned incomplete data from eBay, Etsy, or Amazon.
- On eBay, repeated requests were required to handle error codes such as 400 Bad Request, 404 Not Found, or 500 Internal Server Error.
- The need for architectural patterns for managing API limitations in multi-channel integrations.
2. Connectivity and integration complexity
- A unified set of client connectivity features was required to support multiple programming languages and frameworks.
- Cross-cutting connectivity concerns needed to be offloaded to infrastructure engineers or specialized teams.
- The system had to support cloud and cluster connectivity within a legacy application that was difficult to modify.
3. Reliability and fault tolerance
- High reliability was required through automated integrity checks and retry mechanisms in case of failures.
- Multiple consumer pools were necessary to meet strict performance requirements and isolate issues, ensuring that failures in one queue did not affect others.
4. Sidecar component requirements
- Some components needed to be shared across applications built in different languages or frameworks, making a sidecar approach ideal.
- A component managed by a remote team or external organization had to be integrated in a way that allowed independent updates without disrupting the main application.
- Certain features had to be co-located with the main application, sharing its lifecycle but remaining independently deployable.
- Fine-grained resource control was needed (e.g., memory management per component), which was achieved by deploying the component as a sidecar.
As a result, due to the different limitations of various systems, the project retrieved data more slowly than it could have, and the completeness of data could not be guaranteed, which affected the relevance of statistics.
Comparable complexity appeared in other engagements, such as designing an IoT data pipeline for an energy company on the Azure Cloud, where spanerse sensor streams had to be processed under strict performance and reliability requirements.
Initial infrastructure and architecture
Initially, there was a network of workers, each processing its own data type and specific integration. All rate limits were handled in the same way, based on the worst-case scenario (1 request per minute for all), which ensured reliability but resulted in very slow operation.
How we approached the project
Our dedicated development team understood the assignment — achieving faster data retrieval from Amazon, eBay, Etsy, Shopify, and Quiltt.io APIs.
Amazon, Shopify, eBay, Etsy, and Quiltt.io are to be integrated into this scraping development project. On average, 100000 records per connected client, with numbers growing as more clients are onboarded. At connection, all historical data was retrieved; afterward, daily updates captured all changes.
During the design stage, we developed a comprehensive implementation plan to ensure efficiency, scalability, and business value. The key focus areas were:
- System analysis and architecture design: Conducted in-depth analysis of existing systems and designed an optimal integration architecture tailored to business and technical requirements.
- Custom service development: Built dedicated services for processing financial data, generating reports, and ensuring compliance with industry standards.
- Expert delivery team: Assembled a cross-functional team capable of rapidly implementing solutions, adapting to evolving requirements, and providing continuous support.
- Enterprise system integration: Seamlessly integrated new digital components with the client’s existing customer on-premise system, CRM, ERP, and other enterprise systems to streamline data exchange and improve internal process efficiency.
- Domain and technology expertise: Leveraged sector-specific knowledge to design MVPs, validate assumptions with stakeholders, and provide regular roadmap presentations for transparency and alignment.
- End-to-end software delivery: Designed and deployed specialized software components, including web portals, mobile applications, APIs, and data analytics systems, tailored to meet client needs.
- High reliability and resilience: Implemented automated data integrity checks, retry mechanisms, and error recovery processes to minimize downtime and ensure system stability.
- Advanced analytics and reporting: Enabled fast, accurate access to analytics and statistics to support timely and data-driven decision-making.
- Data accuracy and completeness: Enhanced the quality and reliability of business statistics through robust validation mechanisms.
- Scalability and growth readiness: Architected solutions with the flexibility to scale alongside increasing transaction volumes and client expansion.
- Cost efficiency: Reduced ongoing support and integration costs through reusable codebases and standardized design patterns.
Architecture of the solution
- Microservices architecture for e-commerce data integration
- Separate microservices for statistics and monitoring processing.
- An Ambassador service per integration, enabling scalability based on load.
- One microservice is responsible for handling one task type related to an integration. The task type is tightly coupled to the microservice. This means that each microservice is specialized and dedicated to processing only a single type of task. Under heavy load or increased demand, the microservice can be scaled (horizontally or vertically) to maintain performance.
- At client connection — command to retrieve all data.
- Daily trigger — command to update data.
- Presentation parsing mode for potential clients
Microservices communicated as needed via message queues.
There are three levels. The priority queue was used to define the order of data extraction/processing. This is handled by the master microservice in the master-worker pattern. Processing starts with periods like day, month, half-year, year, etc. Additionally, priority handling is also performed on the Ambassador side, which manages rate distribution. The queue logic:
- Orders
- Transactions
- Remains
- Returns
- Payouts.
Order Items — after the orders have been processed, and have the highest priority regarding fintech data. Demo messages act as the third processing queue with the highest priority in demo mode. For demo purposes, the system limits each customer to 100 requests per marketplace.
How Azure Service Bus was used. Two queues. The first queue was for tasks (the master application, with a consumer rarely involved, only when it was necessary to trigger the next microservice in the processing chain — for example, orders). The second queue was for notifications about task completion.
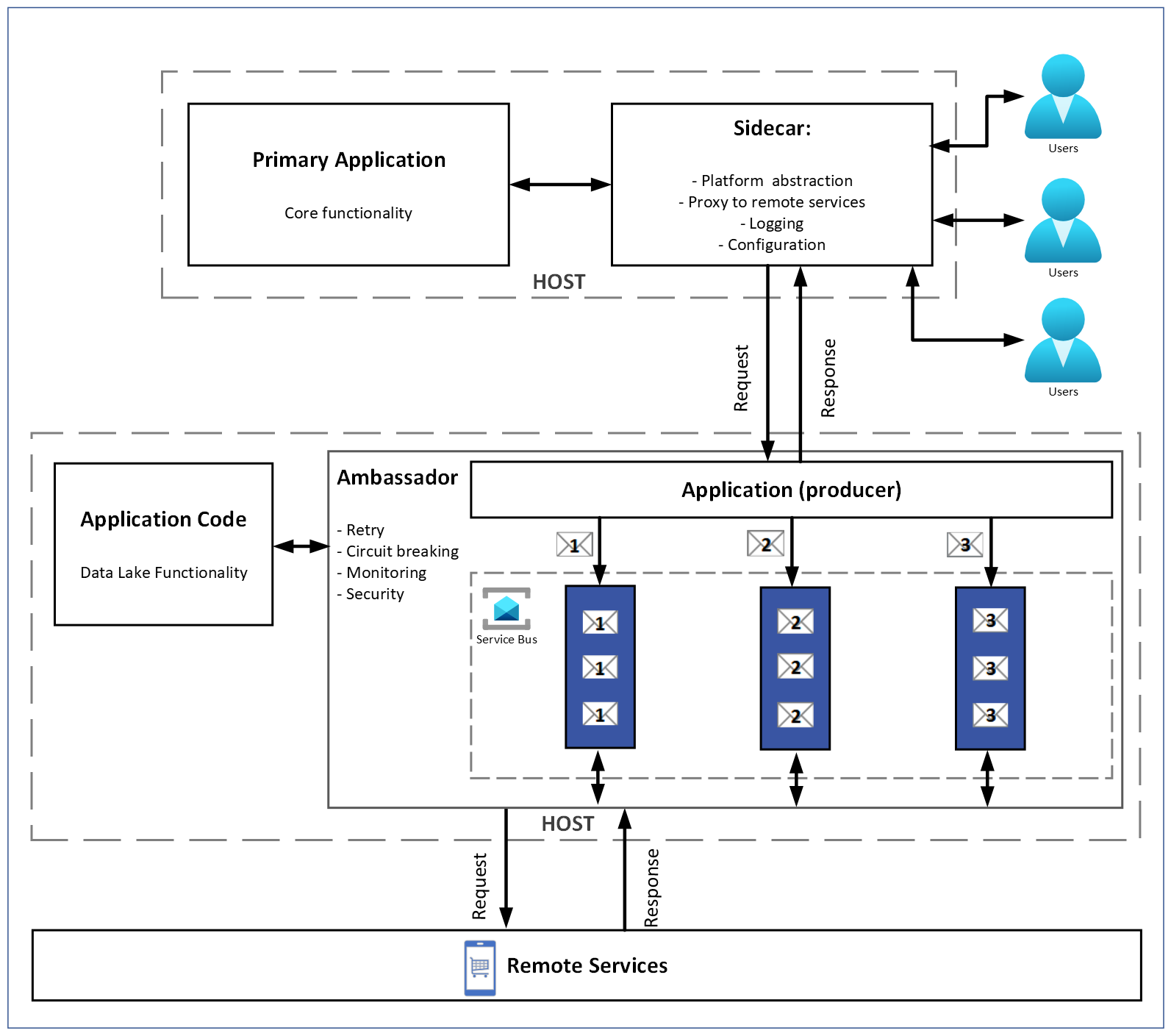
We applied the Competing Consumer pattern in combination with microservices for data retrieval and the Ambassador. All workers with jobs sent their requests to the Ambassador, and the Ambassador determined in which order and proportion they would be processed.
The Sidecar pattern was used to ensure that both dependent apps were deployed together (microservices), the Ambassador, and the data-processing workers.
Additional rules were further elaborated and applied during development:
- Amazon – rate limits are applied per resource (type of data). The Ambassador’s main task here was to slow down the worker to a pace acceptable for the integration.
- Shopify – a single global limit for all requests. In this case, the Ambassador handled priority distribution.
In total, MVP for this component took 3 months.
Technologies used
As part of our technology consulting services, we chose several key technologies for this project. The Ambassador pattern solved the problem of different limitations in different systems while minimizing the amount and complexity of code.
With Ambassador, one code module handled orders (with its limits), another handled Shopify (with its limits), etc., avoiding multiple confusing codebases. For Shopify, requests could be distributed across servers, and synchronization between them was required. The Ambassador acted as a primary gateway server for each integration (data transit points that queue requests until they can be processed).
The Priority Queue allowed request limits to be distributed logically and dynamically according to business needs, based on predefined rules.
For example: Verify the relevance of prices for the store owner’s product groups against similar items offered by competitors on the listed e-commerce platforms, taking into account the stock levels displayed for each product. The store owner defines the priority of product groups to be checked.
Order and order detail requests could be processed in a 1:3 ratio. Once orders were fully loaded, the remaining quota would be reallocated to details, speeding up overall data retrieval.
Other patterns/technologies used:
- Competing Consumer pattern
Fault tolerance and disaster recovery:
- Management logic of the message orchestrator.
- Data loading is split into blocks (the batches into which we spanide data extraction)
- Blocks are sized according to the average data volume.
- Each block loaded as a unit; if incomplete, it was retried.
- Data integrity checks were performed after loading; failures triggered wait-and-retry logic.
- If a message failed 3 times, an email alert was sent to client support; other blocks continued processing.
- All processes were deployed on Microsoft Cloud infrastructure. Azure Blob Storage keeps multiple copies of data to ensure durability and availability, even during failures. Different replication options provide varying levels of protection for choosing the right level of resiliency.
Implementation process
- Discovery/architecture design phase: The client described the problem, we reviewed the existing setup, spent several days brainstorming, proposed the solution, and implemented it.
- Testing integrations and data flow stability: Ran on existing client accounts, cross-checked resulting data.
- Migration from legacy systems or previous integrations: Migration was simplified — for other microservices, only the target URL needed to be replaced.
- Implementation and testing of a proof of concept in partner stores.
We applied the Competing Consumer pattern in combination with microservices for data retrieval and the Ambassador.
This pattern is particularly effective for:
- The application workload can be spanided into tasks that run asynchronously.
- Tasks are independent and can be executed in parallel.
- The workload volume is highly variable and requires scalability.
- The solution must ensure high availability and resilience, even if inspanidual task processing fails.
The Ambassador acted as a coordinator, enforcing integration-specific rules and controlling the execution pace of the workers.
Results and business impact
- Average initial data retrieval and client statistics generation time reduced from 24 hours to 12 hours
- The client was able to retrieve and aggregate large volumes of spanerse data from multiple systems
- They gained a resilient system with automated retries, error recovery, and minimal downtime
- A scalable, flexible microservices architecture was implemented to optimize multi-channel data ingestion
- Faster data retrieval from Amazon, eBay, Etsy, Shopify, and Quiltt.io APIs
- The business received data earlier, enabling faster decision-making
- Improving the accuracy and completeness of statistical data
- Halving the time required to collect complete data and generate reports
- Accelerating business decisions through early access to analytics
- Digital business transformation through the implementation of new technologies and innovative solutions to enhance the client’s business processes and strategy
- Increased productivity through the deployment of solutions to optimize internal processes and automate tasks to improve efficiency and output
- Cost reduction by lowering operational and IT expenses through infrastructure optimization and efficient solutions
- Enhanced customer engagement through improved customer interaction, including better service and new communication opportunities
- Digital transformation by gaining a market edge by leveraging modern technologies and digital solutions
As part of the fintech development process, instead of jumping directly into implementation, our team carried out thorough research of open-banking services and proposed Quiltt.io as the optimal solution. This ensured a reliable and scalable foundation for the client’s financial product
Explore our similar projects to discover how other businesses have benefited from our software development services. If you’re interested in exploring how our expertise can accelerate your digital transformation, visit our Pricing page to discuss your project with our team!
Yuliia Suprunenko